-
Inmarsat-6 F2 دچار مشکلات "بیسابقه" شده است!
Comments Off on Inmarsat-6 F2 دچار مشکلات "بیسابقه" شده است!- Posted by ENoohi
- 29 August 2023
- اخبار

تاریخ خبر: 06/06/1402
به گزارش ViaSAT در بعدازظهر پنجشنبه 02/06/1402، ممکن است ماهواره Inmarsat-6 F2 به دلیل یک ناهنجاری در زیرسیستم برق که در حین بالا بردن مدار رخ داده است، دچار شکست کامل شود . Viasat و سازنده ایرباس در حال رسیدگی به این مشکل و بررسی امکان عملکرد درست این ماهواره در آینده، مطابق با ماموریت آن هستند.
ایرباس با اشاره به اینکه هرگز یک ماهواره مخابراتی در مدارش از کار نیفتاده است، تاکید کرد که مشکل پیشآمده، یک "رویداد بیسابقه" است.
اما ظاهراً این امر برای Viasat بیسابقه نیست، این دومین شکست ماهوارهای اخیر این شرکت میباشد. پنلهای خورشیدی ماهواره پرچمدار این اپراتور (ViaSat-3) مشکل دارد، اما Viasat هنوز آن را به عنوان یک شکست اعلام نکرده است.
در مورد I-6 F2 که SpaceX در ماه فوریه به فضا پرتاب کرد، Viasat گفت که انتظار ندارد بر چشمانداز مالی شرکت برای درآمد و رشد EBITDA (درآمد قبل از بهره، مالیات و استهلاک) تأثیر بگذارد. هدف از این ماهواره افزایش ماهوارههای باند L اینمارست و تکمیل ظرفیت و ارائه پوشش اضافی بود. مارک دانکبرگ، رئیس هیئت مدیره و مدیر عامل Viasat در این خصوص بیان کرد: "ماموریت اولیه I6 F2 اساساً ارائه باند L پشتیبان و 4Gbps ظرفیت اضافی باند Ka، جهت استقرار و راه اندازی یک شبکه انعطاف پذیر و افزونه، بوده."
این ماهواره بر اساس فضاپیمای ایرباس Eurostar E3000، با یک آنتن باند L و شش آنتن باند Ka با بیمهای متعدد ساخته شده است. ضمناً ماهواره دوقلوی آن، I-6 F1، به درستی کار میکند.
Viasat اظهار کرد: "هزینههای ساخت و پرتاب ماهواره بیمه شده است و انتظار میرود موقعیتهای مالی بهبود یابد." پیرو آن در بیانیه روز پنجشنبه اطمینان داد که این شکست تأثیری بر ترازنامه آن شرکت نخواهد داشت. گرچه در صورتی که هر دو ماهواره I-6 F2 و ViaSat-3 دچار خرابی شوند، اپراتور به طور بالقوه در آینده نزدیک دو ادعای بیمه خواهد داشت.
Viasat سه ماهواره باند L دیگر، fleet Inmarsat-8، در دست ساخت دارد تا خدمات امنیتی سراسری این شرکت را تقویت کند. همچنین در رابطه با ظرفیت باند Ka، کنسرسیوم Viasat و Inmarsat به شرکت ترکیبی از 11 ماهواره باند Ka و امکان دسترسی به ماهواره های یکدیگر را میدهد. هفت ماهواره Ka-band دیگر نیز به منظور توسعه خدمات متحرک سراسری این شرکت در دست ساخت است.
-
ایکاست اپراتور برگزیده خدمات فضاپایه در نهمین جشنواره فاوا
Comments Off on ایکاست اپراتور برگزیده خدمات فضاپایه در نهمین جشنواره فاوا- Posted by ENoohi
- 24 August 2023
- اخبار
به گزارش روابط عمومی جشنواره ملی ارتباطات و فناوری اطلاعات، همزمان با روز ملی ارتباطات و فناوری اطلاعات آیین معرفی برگزیدگان نهمین جشنواره ملی ارتباطات و فناوری اطلاعات در سالن شهید قندی وزارت ارتباطات و با حضور عیسی زارع پور، وزیر ارتباطات و فناوری اطلاعات و میثم لطیفی، رئیس سازمان اداری و استخدامی، بعد از وقفهای چند ساله به دلیل شیوع بیماری کرونا، مجدداً برگزار شد. در پایان مراسم برگزیدگان نهمین جشنواره ملی ارتباطات و فناوری اطلاعات اعلام و از آنها تقدیر به عمل آمد.

شرکت عصر ارتباطات بینالملل پارس کار (ایکاست) در زیر محور ارائهدهندگان خدمات فضاپایه به عنوان برگزیده رتبه سوم این جشواره شناخته شد و لوح تقدیر و تندیس این جشنواره توسط آقای علی مرشدسلوک (مدیرعامل ایکاست) از وزیر ارتباطات و فناوری اطلاعات دریافت گردید.

به همین مناسبت ضمن سپاس از مشترکین و همکاران ایکاست که با همراهی خود در کسب این رتبه سهیم بودهاند، این موفقیت را تبریک عرض میکنیم و امیدواریم با تداوم این ارتباط شاهد دستاوردهای روزافزون این مجموعه باشیم.
مشاهده رتبهها در وبسایت وزارت ارتباطات و فناوری اطلاعات:
https://festfava.ict.gov.ir/fa/news
تصاویر بیشتر در خبرگزاری سیتنا:
گزارش تصویری سیتنا از معرفی برگزیدگان نهمین جشنواره فاوا | سیتنا (citna.ir)
-
کسب جایزه برترین اپراتور در سال 1402
Comments Off on کسب جایزه برترین اپراتور در سال 1402- Posted by icasat
- 20 August 2023
- اخبار
نهمین جشنواره ملی ارتباطات و فناوری اطلاعات با حضور شرکتهای فعال در حوزههای گوناگون ICT کشور برگزار و شرکت عصر ارتباطات بین الملل پارس کار (ایکاست) به عنوان اپراتور برگزیده در حوزه مخابرات ماهواره ای انتخاب گردید. کسب این موفقیت را به کلیه مدیران، کارکنان، سهامداران، مشتریان و کلیه ذینفعان این سازمان تبریک و تهنیت عرض نموده و موفقیت بیش از پیش برای پیشبرد اهداف استراتژیک ایکاست را آرزومندیم.

-
ChatGPTچیست؟ یک مدل زبان بزرگ، فناوری پشت آن
Comments Off on ChatGPTچیست؟ یک مدل زبان بزرگ، فناوری پشت آن- Posted by ENoohi
- 25 April 2023
- اخبار
تاریخ خبر: 15/03/2023
مبانی داده ها، موارد استفاده و پروژهها Kurt Muehmel
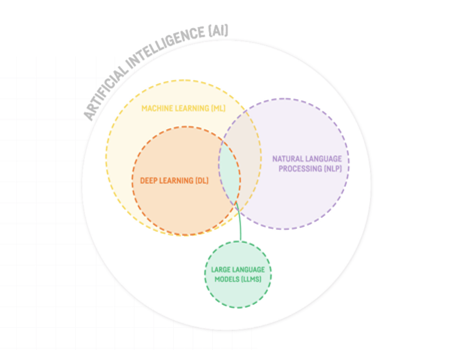
ارائه و معرفی ChatGPT توسط آزمایشگاه تحقیقاتی هوش مصنوعی آمریکایی OpenAI در دسامبر 2022 توجه فوقالعاده را به خود جلب کرده است. این کنجکاوی درمورد هوش مصنوعی به طور کلی تا کلاس فناوری هایی که به طور خاص زیر بنای چت ربات هوش مصنوعی هستند گسترش می یابد. این مدلها که مدلهای زبان بزرگ (LLM) نامیده میشوند، قادر به تولید متن در طیف به ظاهر بیپایانی از موضوعات هستند. درک LLM برای درک نحوه کار ChatGPT کلیدی است.

چیزی که LLM ها را چشمگیر میکند توانایی آنها در تولید متنی شبیه متن نوشته شده توسط انسان در تقریباً هرزبانی (از جمله زبانهای کدنویسی) است. این مدلها یک نوآوری واقعی هستند. هیچ چیز مشابه آنها در گذشته وجود نداشته است.
این مقاله توضیح می دهد که این مدلها چیستند، چگونه توسعه یافته اند و چگونه کار می کنند. وبرای اینکه کاملاً بفهمیم چطور کار میکنند. همانطورکه معلوم است، درک ما از اینکه چرا آنها کار می کنند بسیار ناچیز است.
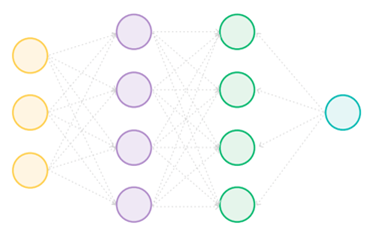
مدل زبان بزرگ (LLM) نوعی شبکه عصبی است
شبکه عصبی نوعی مدل یادگیری ماشینی است که براساس تعدادی توابع کوچک ریاضی به نام نورونها ساخته شده است. مانند نورونهای مغز انسان، آنها پایینترین سطح محاسباتی را دارند.
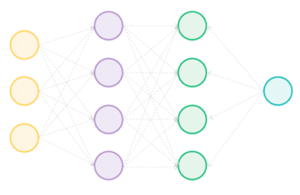
هر نورون یک تابع ریاضی ساده است که یک خروجی را براساس مقداری ورودی محاسبه می کند. با اینحال، قدرت شبکه عصبی از اتصالات بین نورونها ناشی میشود.
هر نورون به برخی از همتایان خود متصل است و قدرت هر اتصال از طریق یک وزن عددی تعیین میشود. آنها درجهای را تعیین میکنند که خروجی یک نورون بعنوان ورودی به نورون بعدی در نظر گرفته میشود.
یک شبکه عصبی میتواند بسیار کوچک باشد. بعنوان مثال، یک نورون پایه میتواند شش نورون با مجموع هشت اتصال بینآنها داشته باشد. بااینحال، یک شبکه عصبی نیز میتواند بسیار بزرگ باشد، همانطور که در مورد LLM ها صدق می کند. اینها ممکن است میلیونها نورون با صدها میلیارد اتصال بین آنها داشته باشند که هر اتصال وزن خاص خود را دارد.
یک LLM از معماری ترانسفورماتور استفاده میکند
ما تا کنون میدانستیم که LLM نوعی شبکه عصبی است. بهطور خاص ، LLMها از معماری شبکه عصبی خاصی به نام ترانسفورماتور یا مبدل استفاده میکنند که برای پردازش و تولید داده های متوالی مانند متن طراحی شده است.
معماری در این زمینه نحوه اتصال نورونها به یکدیگر را توصیف میکند. همه شبکه های عصبی نورون های خود را در چندین لایه مختلف گروهبندی میکنند. اگر لایههای زیادی وجود داشته باشد، شبکه بعنوان «عمیق» توصیف میشود، که اصطلاح «یادگیری عمیق» از آنجا آمده است.
در یک معماری شبکه عصبی بسیار ساده، هر نورون ممکن است به هریک از نورونها در لایه بالای خود متصل شود. در برخی دیگر، یک نورون ممکن است فقط به برخی از نورونهای دیگر که در نزدیکی آن در یک شبکه قرار دارند متصل شود.
مورد دوم در شبکههای عصبی کانولوشنال (CNN) وجود دارد. سیانانها پایهواساس تشخیص تصویر مدرن را در دهه گذشته تشکیل دادهاند. این واقعیت که CNN در یک شبکه (مانند پیکسل های یک تصویر) ساختار یافته است تصادفی نیست. درواقع، این دلیل مهمی است برایاینکه چرا آن معماری برای دادههای تصویری به خوبی کار میکند.
بااینحال، ترانسفورماتور تاحدودی متفاوت است. یک ترانسفورماتور که در سال 2017 توسط محققان گوگل ساخته شد، ایده «توجه» را معرفی میکند، به موجب آن نورونهای خاصی که قویتر هستند به نورونهای دیگر در یک توالی متصل میشوند یا «به آنها توجه بیشتری میکنند».
از آنجایی که متن در یک دنباله خوانده می شود، یک یپساز دیگری، با بخشهای مختلف یک جمله که به دیگران اشاره میکند یا آن را تغییر میدهد (مانند صفتی که اسم را تغییر میدهد اما فعل را تغییر نمیدهد) همچنین تصادفی نیست که معماری ای که برای کار متوالی، با نقاط قوت ارتباط متفاوت بین بخشهای مختلف آن دنباله ساخته شده است، باید روی دادههای متنی به خوبی کار کند.
یک LLM خودش را میسازد
بعبارت سادهتر، مدل LLM یک برنامه کامپیوتری است. مجموعهای از دستورالعملها است که محاسبات مختلفی را روی دادههای ورودی خود انجام میدهد و یک خروجی ارائه میدهد.
با اینحال، چیزی که در مورد یادگیری ماشین یا مدل هوش مصنوعی مهم است، این است که به جای نوشتن آن دستورالعملها به طورصریح، در عوض برنامه نویسان انسانی مجموعهای از دستورالعملها (یک الگوریتم) را می نویسند که سپس حجم زیادی از دادههای موجود را برای تعریف خود مدل بررسی میکند. به اینترتیب، برنامه نویسان انسانی مدل را نمیسازند، بلکه الگوریتمی را میسازند که مدل را میسازد.
در مورد LLM، این بدان معناست که برنامه نویسان معماری مدل و قوانینی را که براساس آن ساخته میشود، تعریف میکنند. اما آنها نورونها یا وزنههای بین نورونها را ایجاد نمیکنند. این در فرآیندی به نام "آموزش" انجام میشود که در طی آن مدل، به دنبال دستورالعمل های الگوریتم، خود آن متغیرها را تعریف میکند.
در مورد LLM، دادهای که بررسی میشود متن است. دربرخیموارد، ممکن است تخصصیتر یا عمومیتر باشد. در بزرگترین مدلها، هدف، ارائه هرچهبیشتر متن دستوری به مدل برای یادگیری است.
در ابتدا، خروجی نامفهوم است، اما ازطریق یک فرآیند عظیم آزمونوخطا و با مقایسه مداوم خروجی آن با ورودی آن کیفیت خروجی بهتدریج بهبود مییابد و متن قابل فهمتر میشود.
باتوجه به زمان کافی، منابع محاسباتی کافی و دادههای آموزشی کافی، مدل یاد میگیرد که متنی را تولید کند که برای خواننده انسانی، از متن نوشته شده توسط انسان قابل تشخیص نیست. در برخی موارد، خوانندگان انسانی ممکن است بازخوردی را به شکل نوعی مدل پاداش ارائه دهند و زمانی که متن بهخوبی خوانده میشود یا زمانی که خوانده نمیشود بهآن بگویند (به این میگویند «یادگیری تقویتی از بازخورد انسانی» یا RLHF). مدل این را در نظر میگیرد و بهطورمداوم خود را براساس آن بازخورد بهبود میبخشد.
یک LLM پیشبینی میکند که کدام کلمه باید کلمه قبلی را دنبال کند
یک توصیف بسیار ساده از LLMها ایناست که آنها «بهسادگی کلمه بعدی را در یک دنباله پیشبینی میکنند». این درست است، اما این واقعیت را نادیده میگیرد که این فرآیند ساده می تواند به این معنی باشد که ابزارهایی مانند ChatGPT متن با کیفیت بسیار بالایی تولید میکنند. به همین سادگی میتوان گفت که «مدل به سادگی محاسبه ریاضی انجام میدهد»، که این نیز درست است، اما برای کمک به درک نحوه عملکرد مدل یا درک قدرت آن چندان مفید نیست.
نتیجه فرآیند آموزشی که در بالا توضیح داده شد یک شبکه عصبی با صدها میلیارد اتصال بین میلیونها نورون است که هرکدام توسط خود مدل تعریف شدهاند. بزرگترین مدلها حجم زیادی از دادهها را نشان میدهند، شاید چند صد گیگابایت فقط برای ذخیره تمام وزنها.
هریک از وزنها و هریک از نورونها یک فرمول ریاضی است که باید برای هر کلمه (یا دربرخی موارد، بخشیاز یک کلمه) که برای ورودی آن دراختیار مدل قرار میگیرد و برای هر کلمه (یا بخشی از یک کلمه) محاسبه شود که به عنوان خروجی خود تولید میکند.
این جزئیات فنی است، اما به این «کلمات کوچک یا بخشهایی از کلمات» «نشانها» یا «توکن ها» گفته میشود، که معمولاً وقتی استفاده از این مدلها بعنوان یک سرویس ارائه میشوند، قیمتگذاری میشود. در ادامه در مورد آن بیشتر توضیح خواهیم داد.
کاربر درحال تعامل با یکیاز این مدلها، ورودی را در قالب متن ارائه میدهد. برای مثال، میتوانیم دستور زیر را به ChatGPT ارائه کنیم:
سلام ChatGPT ، لطفا یک توضیح 100 کلمهای از Dataiku به من ارائه دهید.
شرحی از نرمافزار و ارزش اصلی آن را درج کنید
سپس مدلهای پشت ChatGPT این درخواست را به توکن تبدیل میکنند. به طور متوسط، یک نشانه ⅘ از یک کلمه است، بنابراین دستور بالا و 23 کلمه آن ممکن است منجربه حدود 30 نشانه شود. مدل GPT-3 که مدل gpt-3.5-turbo مبتنی بر آن است، 175 میلیارد وزن دارد، به این معنی که 30 توکن متن ورودی به 30x 175 میلیارد = 5.25 تریلیون محاسبات منجر میشود. مدل GPT-4 که در ChatGPT نیز موجود است، دارای وزن نامشخصی است.
سپس، مدل شروع به تولید پاسخی میکند که براساس حجم متنی که درطول آموزش مصرف کرده، درست به نظر میرسد. نکته مهم این است که چیزی در مورد سوال جستجو نمیکند. هیچ حافظهای ندارد که بتواند «dataiku»، «value proposition»، «software» یا هرعبارت مرتبط دیگری را جستجو کند. درعوض، تولید هر نشانه متن خروجی را آغاز میکند، 175 میلیارد محاسبات را دوباره انجام میدهد، و رمزی را تولید میکند که به احتمال قویتر درست به نظر می رسد.
LLMها متنی را تولید میکنند که درست به نظر میرسد اما نمی توانند تضمین کنند که درست باشد.
ChatGPT نمیتواند تضمینی برای درست بودن خروجیش ارائه دهد، آن فقط درست به نظر میرسد. پاسخهای آن در حافظهاش جستجو نمیشوند آنها بر اساس 175 میلیارد وزنی که قبلاً توضیح داده شد، ایجاد میشوند.
این نقص مختص ChatGPT نیست، بلکه مربوط به وضعیت فعلی همه LLMها است. آنها مهارتی در یادآوری واقعیات ندارند. سادهترین پایگاههای داده این کار را بهخوبی انجام میدهند. در عوض، نقطهقوت آنها در تولید متنی است که مانند متن نوشته شده توسط انسان خوانده میشود و خوب بهنظر میرسد. در بسیار یاز موارد، متنی که درست به نظر میرسد نیز درواقع درست خواهد بود، اما نه همیشه.
در آینده، این احتمال وجود دارد که LLMها در سیستمهایی ادغام شوند که قدرت تولید متن LLM را با یک موتور محاسباتی یا پایگاه دانش ترکیب میکنند تا پاسخهای واقعی را در متن زبانطبیعی بصورت قانع کنندهای ارائه دهند. آن سیستمها امروزه وجود ندارند، اما بهراحتی میتوان تخمین زد که چقدر طول میکشد تا آنها را ببینیم.
امکان دیگر این است که اگر میخواهید اطلاعاتی را که قبلاً دارید در قالب پاسخ زبان طبیعی به کاربران ارائه دهید، میتوانید آن پاسخها را به ابزارهایی مانند ChatGPT ارائه دهید و از آنها بخواهید براساس آن پاسخها جوابی بسازند. Dataiku یک نسخه نمایشی با استفاده از GPT-3 برای ارائه پاسخ از اسناد Dataiku ایجاد کرده است که دقیقاً این کار را انجام میدهد.
آیا GPT-4 یک LLM است؟
در 14 مارس 2023، OpenAI ، آخرین نسخه از مدلهای خود را در خانواده GPT به نام GPT-4 منتشر کرد. علاوه بر تولید متن با کیفیت بالاتر درمقایسه با GPT-3.5، GPT-4 توانایی تشخیص تصاویر را نیز ارائه میدهند. ممکن است قادر به تولید تصاویر نیز باشد. بااینحال، این قابلیت، اگر وجود داشته باشد، هنوز دردسترس نیست. توانایی مدیریت دادههای ورودی و خروجی از انواع مختلف (متن، تصاویر، ویدئو، صدا و غیره) به این معنی است که GPT-4 چندوجهی است.
اصطلاحات مربوط به این مدلهای آخر به سرعت درحال تکامل است، مطابق با برخی از بحثها در جامعه متخصص استدلال میشود که "مدل زبان" بسیار محدودکننده است. اصطلاح "مدل بنیاد" توسط محققان در استنفورد رایج شده است، اما همچنین منبع بحثهایی است. مانند خود فناوری، زبان مورد استفاده برای توصیف فناوری بهسرعت به تکامل خود ادامه خواهد داد.
استفاده از ChatGPT، GPT-4 و مدلهای زبان بزرگ (LLM) در سازمان
ما از ChatGPT و یکی از مدلهای آن، gpt-3.5-turbo، بعنوان مثال در سراسر این مقاله استفاده کردهایم، اما این تنها یک مدل و یک محصول در میان بسیاری از آنها است. برخی از LLMها اختصاصی هستند و ازطریق یک رابط وب یا یک API مانند ChatGPT قابل دسترسی هستند. سایر LLM ها منبع باز (open source) هستند و اگر توان محاسباتی و مهارت لازم برای انجام این کار را داشته باشند، میتوانند توسط یک دانشمند یا مهندس داده باهوش دانلود و اجرا شوند. برای هر رویکرد جانشینهایی وجود دارد.
-
بازخورد مثبت مشتریان در پاییز 1401 نسبت به سرویس ایکاست
Comments Off on بازخورد مثبت مشتریان در پاییز 1401 نسبت به سرویس ایکاست- Posted by ENoohi
- 19 April 2023
- اخبار
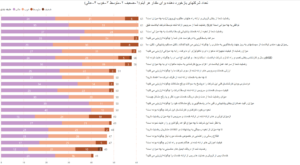
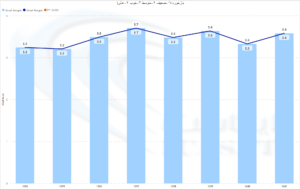
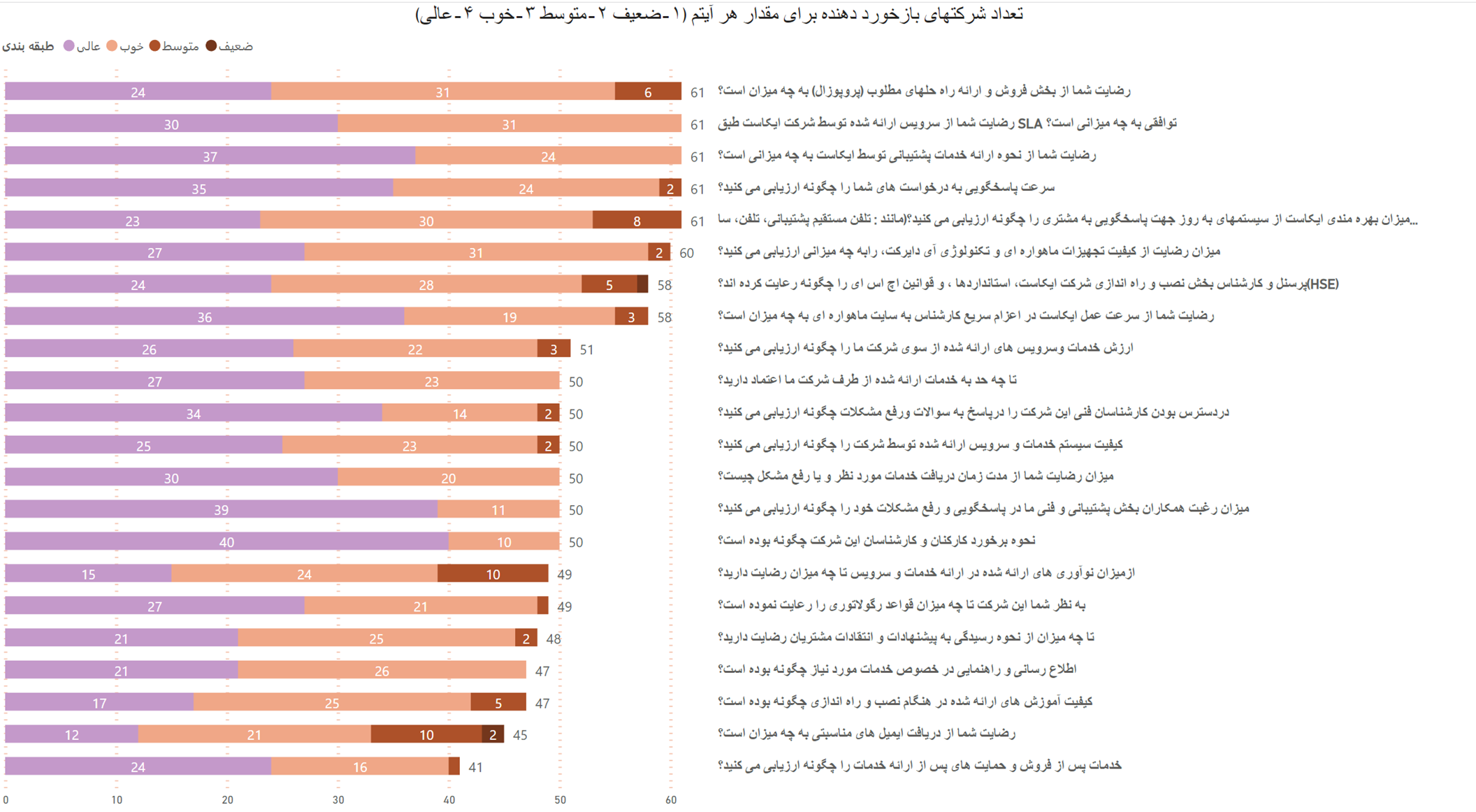
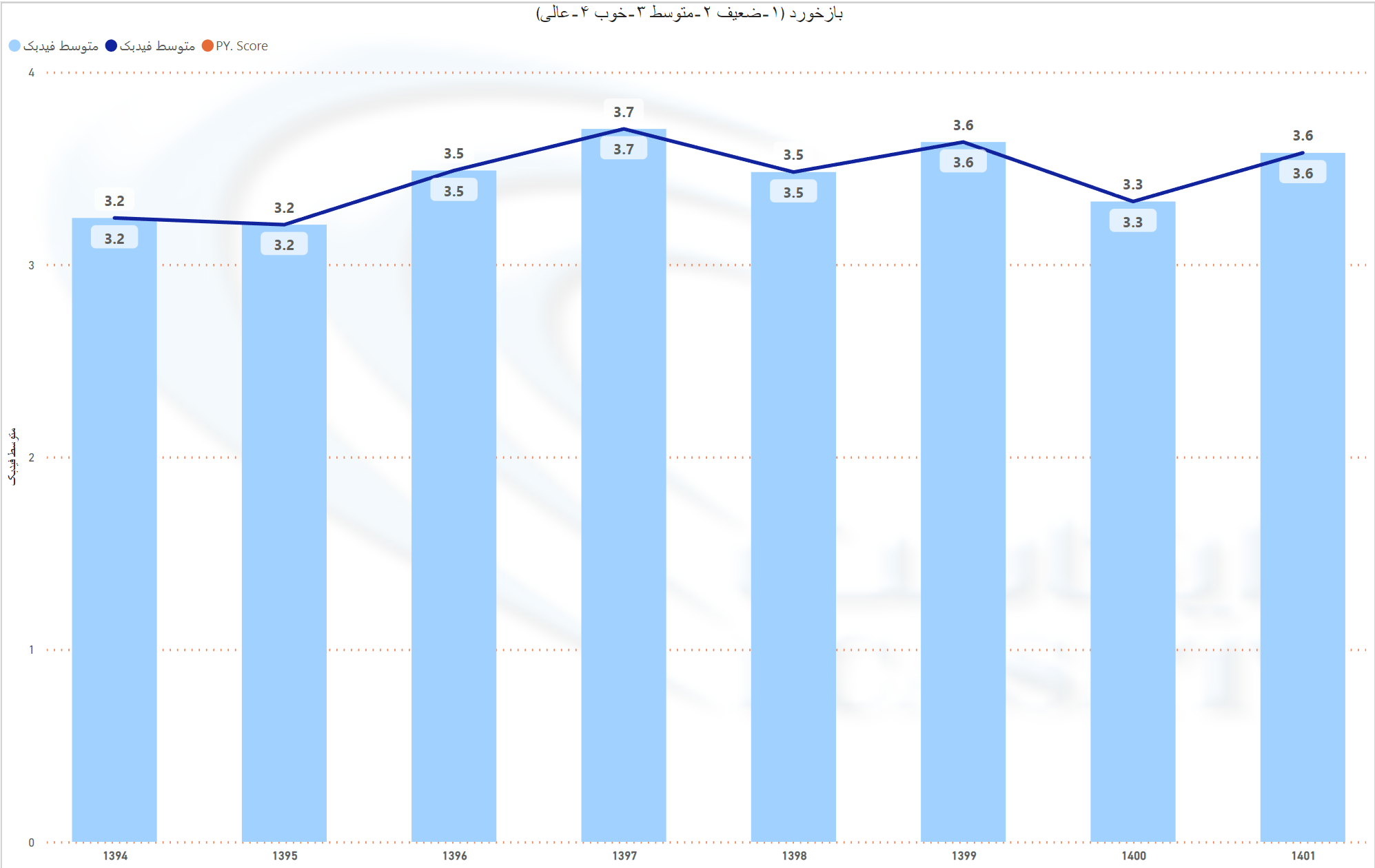
شرکت ایکاست مفتخر است که در راستای ارائه خدمات و سرویس های بهتر به مشتریان گرامی اقدام به نظر سنجی دوره ای نموده و اعلام می دارد که طبق تحلیل آماری بازخورد مشتریان موفق به کسب متوسط امتیاز 3.6 از 4 با روش طیف لیکرت و امتیاز 73 از 100 با روش ان پی اس شده است.