-
پاویون ج.ا.ایران در چهل و چهارمین نمایشگاه بین المللی فناوری اطلاعات و ارتباطات جیتکس
Comments Off on پاویون ج.ا.ایران در چهل و چهارمین نمایشگاه بین المللی فناوری اطلاعات و ارتباطات جیتکس- Posted by icasat
- 19 August 2024
- اخبار

-
بروشور نمایشگاه بین المللی فناوری اطلاعات، ارتباطات و برق پایدار کیش
Comments Off on بروشور نمایشگاه بین المللی فناوری اطلاعات، ارتباطات و برق پایدار کیش- Posted by icasat
- 19 August 2024
- اخبار

-
گوگل با پیکسل 9 ویژگی SOS ماهواره ای را به اندروید می آورد
Comments Off on گوگل با پیکسل 9 ویژگی SOS ماهواره ای را به اندروید می آورد- Posted by icasat
- 17 August 2024
- اخبار
گوگل در 13 آگوست اعلام کرد که گوشی جدید پیکسل 9 شامل SOS Satellite (اعلام درخواست کمک SoS از طریق ماهواره و بخصوص در مکانهایی که گوشی به هیچوجه آنتن نمی دهد) خواهد شد.
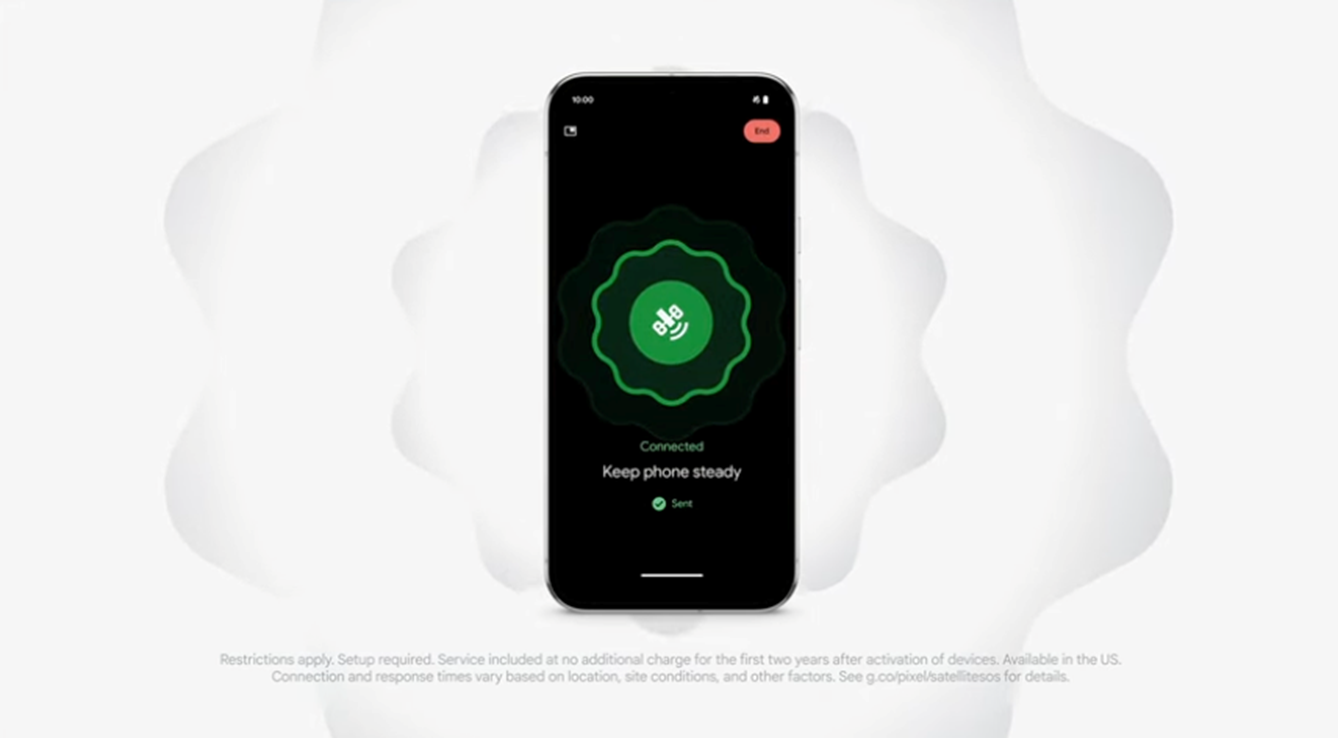
گوگل قابلیتهای ماهوارهای را به گوشی جدید پیکسل 9 خود اضافه میکند تا پیامهای اضطراری را خارج از شبکههای تلفن همراه ارائه دهد.
با توجه به اعلامیه گوگل پیکسل 9 در 13 آگوست، پیکسل 9 اولین گوشی اندرویدی خواهد بود که از SOS ماهواره ای بهره می برد. این سرویس به کاربران این امکان را می دهد که بدون خدمات تلفن همراه با امدادگران اضطراری تماس بگیرند و مکان را از طریق ماهواره به اشتراک بگذارند. گوگل اعلام کرد که این سرویس ابتدا در ایالات متحده در دستگاههای پیکسل 9 در هر طرح شرکت مخابراتی در دسترس خواهد بود. این سرویس برای دو سال اول رایگان خواهد بود.
گوگل با شرکتهای Skylo و Garmin روی این ویژگی کار می کند.
گوگل در تجهیز گوشی ها به قابلیت اتصال مستقیم به ماهواره ها از اپل پیروی می کند. اپل در سال 2022 قابلیتهای ماهوارهای را به آیفون 14 معرفی کرد و اخیراً دسترسی آن را فراتر از پیامهای اضطراری گسترش داده است و به کاربران اجازه میدهد زمانی که شبکههای تلفن همراه در دسترس نیستند، پیامهای منظم ارسال کنند. اپل با Globalstar برای بخش ماهواره همکاری می کند.
Skylo از ماهواره های خود استفاده نمی کند - این شرکت یک ارائه دهنده خدمات شبکه غیرزمینی (NTN) است که با چندین اپراتور ماهواره ای با طیف مجاز کار می کند. فناوری این شرکت پیوندهای ماهوارهای را به دستگاههای سلولی در انواع منظومه ماهواره ای بهینه میکند و زیرساخت شبکه دسترسی رادیویی در ایستگاههای زمین در سطح جهانی نصب شده است.
پارث تریودی، یکی از بنیانگذاران و مدیر عامل Skylo، اظهار داشت: «اسکایلو مفتخر است که شریک خدمات ماهوارهای Google Pixel باشد. خدمات ما با تیمهای پیکسل و اندروید در Google و همچنین تمام شرکای اکوسیستم پشتیبان ما به دقت توسعه داده شده است.
Skylo که در اوایل سال جاری 37 میلیون دلار بودجه جمع آوری کرد، بیش از 10 میلیون پیام را از طریق شبکه ماهواره ای خود ارسال کرده است.
همچنین گارمین اعلام کرد که سرویس پاسخ اضطراری SOS ماهوارهای آن در اکوسیستم گوشیهای هوشمند اندرویدی گوگل ادغام شده است تا این امکان را فراهم کند. بر اساس این قرارداد، کاربران Pixel در ایالات متحده ممکن است بتوانند با خدمات هماهنگی پاسخ اضطراری Garmin Response در زمانی که پوشش تلفن همراه و Wi-Fi با استفاده از ویژگی SOS ماهواره Pixel در دسترس نیست، ارتباط برقرار کنند.
گارمین در توضیح نحوه عملکرد این سرویس گفت که هماهنگکنندگان حوادث اضطراری اطلاعات را جمعآوری کرده و شبکه سازمانهای مجری قانون، ارائهدهندگان خدمات اضطراری، متخصصان جستجو و نجات، سفارتها، گارد ساحلی و غیره را فعال میکنند.
گارمین از این فرصت برای گسترش خدمات هماهنگی پاسخ اضطراری ماهواره ای اثبات شده و ممتاز خود به اکوسیستم اندروید استقبال می کند، که با Google Pixel 9 در ایالات متحده شروع می شود هر ساله، Garmin Response از هزاران فعال سازی SOS پشتیبانی می کند که احتمالاً در این فرآیند جان انسان ها را نجات می دهد. گارمین اعلام کرد ما مشتاقانه منتظر همکاری با Google هستیم تا به مردم کمک کنیم در صورت نیاز به خدمات اضطراری متصل شوند."
گوگل اشاره کرد که این اولین گوشی اندرویدی است که دارای اتصال ماهواره ای است. کوالکام قبلا تراشهای را توسعه داده بود که با شبکه ماهوارهای ایریدیوم برای تلفنهای همراه اندروید سازگار بود، اما کوالکام سال گذشته پس از عدم حضور سازندگان به این قرارداد پایان داد.
اکوسیستمی که ماهوارهها را مستقیماً به تلفنهای همراه متصل میکند به سرعت در حال توسعه است، زیرا تولیدکنندگان تجهیزات مختلف و ارائهدهندگان شبکه با شرکتهای ماهوارهای همکاری میکنند. به عنوان مثال، اسپیس ایکس اکنون در حال آزمایش ماهواره های Starlink برای ارتباط مستقیم به گوشی های همراه با شریک T-Mobile خود است. و ورایزون اخیراً قراردادی 100 میلیون دلاری با AST SpaceMobile برای خدمات ماهواره ای مستقیم به تجهیزات همراه برای مشتریان خود اعلام کرده است.
منبع سایت : satellitetoday
-
فراخوان آزمایشگاه مرجع ارزیابی محصولات و خدمات پایه هوش مصنوعی
Comments Off on فراخوان آزمایشگاه مرجع ارزیابی محصولات و خدمات پایه هوش مصنوعی- Posted by icasat
- 17 August 2024
- اخبار

-
مروری بر برنامه پیشنهادی وزارت ارتباطات و فناوری اطلاعات دولت چهاردهم
Comments Off on مروری بر برنامه پیشنهادی وزارت ارتباطات و فناوری اطلاعات دولت چهاردهم- Posted by icasat
- 17 August 2024
- اخبار
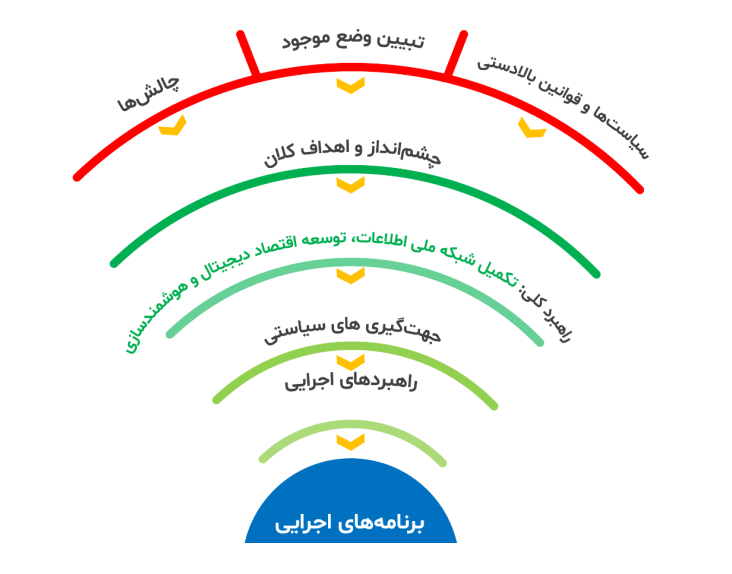
در سند حاضر، ضمن بررسی سیاست های بالا دستیی و ملی، وضع موجود و چالش های اساسی شناسایی شده اند و با ارائه یک راهبرد کلی منطبق بر چشم انداز و اهداف طراحی شده در اسناد ملی، برای دستیابی به اهداف کلان، جهت گیری های سیاستی و برنامه های اجرایی مشخصی ارائه شده اند. الگوی ارائه شده برای رسیدن به برنامه ها ذیل قابل بررسی است.